预测蛋白质配对的算法可以帮助显示生命系统如何工作
模拟细胞内蛋白质如何相互作用的算法将加强对生物学的研究,并阐明蛋白质如何协同工作以完成诸如将食物转化为能量等任务。研究人员开发了一种算法,通过识别细胞内的哪些蛋白质相互作用,基于它们的基因序列,帮助我们理解生命系统的工作原理。
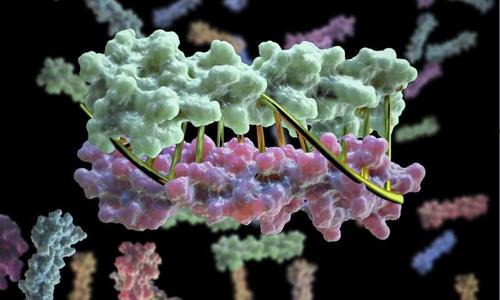
在过去的十年中,从基因测序中产生大量数据的能力迅速发展,但研究人员的麻烦在于能够应用序列数据来更好地理解生命系统。发表在“ 美国国家科学院院刊”上的这项新研究向前迈出了重要一步,因为生物过程,例如我们的身体如何将食物转化为能量,是由特定的蛋白质 - 蛋白质相互作用驱动的。
研究报告的共同作者,剑桥大学化学系的Lucy Colwell博士与Ned Wingreen一起领导了这项研究,“我们真的很惊讶我们的算法足够强大,能够在没有实验数据的情况下做出准确的预测。”普林斯顿大学。“能够预测这些相互作用将有助于我们了解蛋白质如何适应并协同工作以完成所需的任务 - 使用算法比依靠实验更快,更便宜。”
当蛋白质相互作用时,它们粘在一起形成蛋白质复合物。在她之前的研究中,Colwell发现如果已知两种相互作用的蛋白质,可以使用序列数据来确定这些复合物的结构。一旦知道了复合物的结构,研究人员就可以研究化学上发生的情况。然而,哪些蛋白质相互作用的问题仍然需要昂贵,耗时的实验。每个细胞通常包含相同蛋白质的多个版本,并且不可能预测每种蛋白质的哪个版本会特异性地相互作用 - 相反,实验涉及尝试所有选项以查看哪些蛋白质粘附。
在目前的论文中,研究人员使用数学算法筛选可能的相互作用伙伴,并识别彼此相互作用的蛋白质对。该方法正确地预测了配对已知的超过40,000个蛋白质序列的数据集中存在的93%的蛋白质 - 蛋白质相互作用,而没有首先提供正确配对的任何实例。
当两种蛋白质粘在一起时,一条链上的一些氨基酸会粘附在另一条链上的氨基酸上。相互作用蛋白质之间的界限趋向于随着时间的推移一起进化,导致它们的序列彼此镜像。
该算法使用此效果来构建交互模型。它首先随机配对每个生物体内的蛋白质版本 - 因为相互作用的配对在序列上往往比非相互配对更相似,该算法可以从随机起点快速识别出一小组大致正确的配对。
使用这个小集合,算法测量第一蛋白质中特定位置的氨基酸是否影响第二蛋白质中特定位置发生的氨基酸。从数据中学习的这些依赖性被整合到模型中并用于计算每种可能的蛋白质对的相互作用强度。消除了低得分配对,剩余的配置用于构建更新的模型。
研究人员认为,只有通过研究在实验中发现的对,才能首先“学习”制造良好蛋白质 - 蛋白质对的算法,该算法才能正常工作。这意味着研究人员必须为算法提供一些已知的蛋白质对或“黄金标准”,以便比较新序列。该团队使用了两个经过充分研究的蛋白质家族,组氨酸激酶和反应调节因子,它们作为细菌信号系统的一部分相互作用。
但是已知的例子通常很少,并且在细胞中存在数千万未发现的蛋白质 - 蛋白质相互作用。所以团队决定看看他们是否可以减少他们给算法的训练量。他们逐渐降低了他们喂入算法的已知组氨酸激酶反应调节剂对的数量,并惊讶地发现该算法继续有效。最后,他们运行算法而没有给出任何这样的训练对,并且它仍然预测新对具有93%的准确度。
“我们不需要一套训练数据的事实真的令人惊讶,”科尔韦尔说。
该算法是使用来自细菌的蛋白质开发的,研究人员现在将该技术扩展到其他生物体。“生物体内的反应是由特定的蛋白质相互作用驱动的,”科尔韦尔说。“这种方法使我们能够识别和探索这些相互作用,这是建立生命系统如何运作的重要一步。”
推荐内容
-
量子生物学的真实历史
量子生物学是一种年轻且越来越流行的科学类型,并不像许多人所认为的那样新,有着复杂而有些黑暗的历史,解释了世界上第一个量子生物学...
-
当脂肪细胞改变颜色
在哺乳动物中,存在三种类型的脂肪组织。白色脂肪细胞主要位于身体的腹部和皮下区域,非常适合储存多余的能量。相反,米色和棕色脂肪细...
-
树兰医疗:隔离结束,6岁女童的爸爸给“大白们”写了一封感谢信
非常感谢你们每一位的努力和付出,你们辛苦了! 大年三十晚上,我的女儿被开水烫伤手臂,是你们树兰医院驻点的医疗团队第一时间在群里告知
-
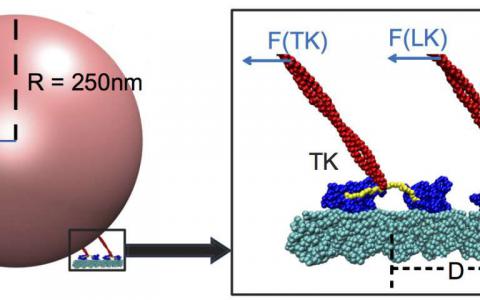
Kinesins在承受重载时无视弱力
如果你是前面的运动蛋白,准备做重拉。这是莱斯大学领导的关于驱动驱动蛋白的机制的一个结论,驱动蛋白是在细胞内携带货物的运动蛋白。...
-
苏宁美的超品日,拯救囧味年!
春节是中国人一年中最重要的节日,承载着中国人对于家庭以及亲戚朋友难以割舍的感情寄托,团圆对于每一个中国人来说有着崇高的意义。但...
-
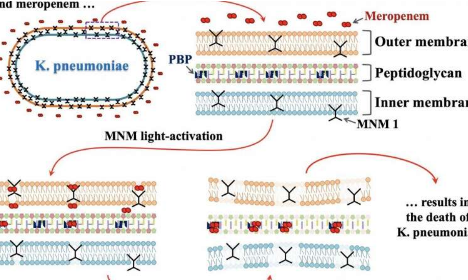
分子演习摧毁了致命的超级细菌
分子钻具有靶向和消灭致命细菌的能力,这些细菌对几乎所有抗生素都产生了抗药性。在某些情况下,演习会使抗生素再次有效。赖斯大学,德...
-
进口降脂药选什么成分的好?
近些年来,高血脂在我们生活中算是名噪一时很多人都对这个词比较熟悉,一般来说高血脂在中老年人单重发病率比较高,但是这几年数据...
-
研究人员在加利福尼亚中部附近的海底发现了神秘的洞
在最近一次对大苏尔海域深海底的调查中,MBARI研究人员在海底发现了数千个神秘的洞或坑。科学家和资源管理者希望了解这些坑的形成方式,因
-
一种新的高效的和选择性的抗疟疾分子
一种新的实验室合成分子,基于在海洋滑翔细菌中发现的称为marinoquinolines的天然化合物,是开发新抗疟药物的有力候选者。在测试中,该分子
-
超分辨率显微镜可以显示维持细胞极性的机制
细胞不是均匀的球体; 它们通常有各种不同的形状。在最广泛的意义上,这种形状的变化被称为细胞极性,并且它是各种细胞功能的基本特性。根