第一个微生物专家来自数千篇论文
虽然最近的报告显示存在超过114,000,000份已发表的科学文献的文件,但找到一种方法来改善对这种知识的获取并有效地综合它成为一个日益紧迫的问题。
为了解决这个问题,英国科学家Ross Mounce和剑桥大学的Peter Murray-Rust以及巴斯大学的Matthew Wills使用公布的人物图像中的机器专门提取的数据进行了世界上第一次自动化超级建筑的尝试。他们的研究结果发表在开放科学期刊Research Ideas and Outcomes(RIO)上。
在他们的研究中,研究人员选择了国际系统学和进化微生物学杂志(IJSEM) - 唯一一个托管所有新的有效描述的原核分类群的存储库,因此,它是测试自动和半自动合成系统的最佳选择。已发表的系统发育。据作者称,IJSEM每年发布的系统发育树图像数量超过任何其他期刊。
系统地下载了可追溯到2003年1月的11年篇文章,以便提取系统发育树形图的所有图像文件进行分析。然后,计算机视觉技术允许将图像自动转换回可重复使用的,可计算的系统发育数据,并用于所有证据的正式超树合成。
在他们的研究过程中,科学家们必须克服版权所带来的各种挑战,正式涵盖他们为工作目的所需的几乎所有文件。在这一点上,他们面临着一个相当矛盾的问题 - 虽然科学文献中出版的数据的易于访问和重复使用得到普遍支持和强烈推动,但是通用版权实践使得科学家在将先前编译的数据合并到自己的数据时很难有信心。工作。作者讨论了英国版权法的最新变化,这些变化使他们的工作能够看到光明的一天。因此,他们将其输出作为事实提供,并使用Creative Commons的CC0豁免将其分配到公共领域,以使任何人无忧无虑地重复使用。
“我们现在处于这样一个阶段:没有人有时间阅读所有已发表论文的标题,更不用说摘要了,”作者评论道。
“我们相信机器现在必不可少,使我们能够理解已发表科学的流程,本文还讨论了实现这一目标所固有的几个关键问题。”
“我们故意选择文献的一个小节(限于一个期刊)来减少体积,速度和变化,主要集中在有效性上。我们要问,从半结构化科学文献中提取数据的高通量机器是否可行和有价值。 “
推荐内容
-
江苏全部解封预计时间 常州全部解封还要多久
提醒:疫情期间,请牢记新冠肺炎十大症状:发热(体温≥37 3℃)、干咳、乏力、嗅觉和味觉减退、鼻塞、流涕、咽痛、结膜炎、肌痛、腹泻...
-
跳单是什么意思违法吗?跳单行为怎么定义有什么后果
【导读】什么是跳单?据消息显示,跳单行为亦称为跳中介,买家跳过中介而私自与卖家签订买卖合同。中介方经常会遇到这种情况,而且以房东居
-
遗传科学家识别与慢性山区疾病相关的两个基因
根据一个大型跨国研究团队的研究,两个基因 - 血细胞调节因子SENP1和癌症相关基因ANP32D--在高山病中起着关键作用,也称为Monge病。大约
-
实验疫苗可保护猕猴免受HIV感染
由宾夕法尼亚州斯克里普斯研究所,哈佛大学医学院的研究人员领导的一项研究表明,恒河猴(Macaca mulatta)可以被提示产生针对一种HIV病毒的
-
鲁豫节目被嘉宾打怎么回事?鲁豫被嘉宾打了吗事件始末
鲁豫被嘉宾打了吗?嘉宾想打鲁豫是怎么回事?而对于鲁豫被嘉宾打了吗的这个话题,今天的你是否也在关注着?究竟什么情况?下面跟小编一起来了解
-
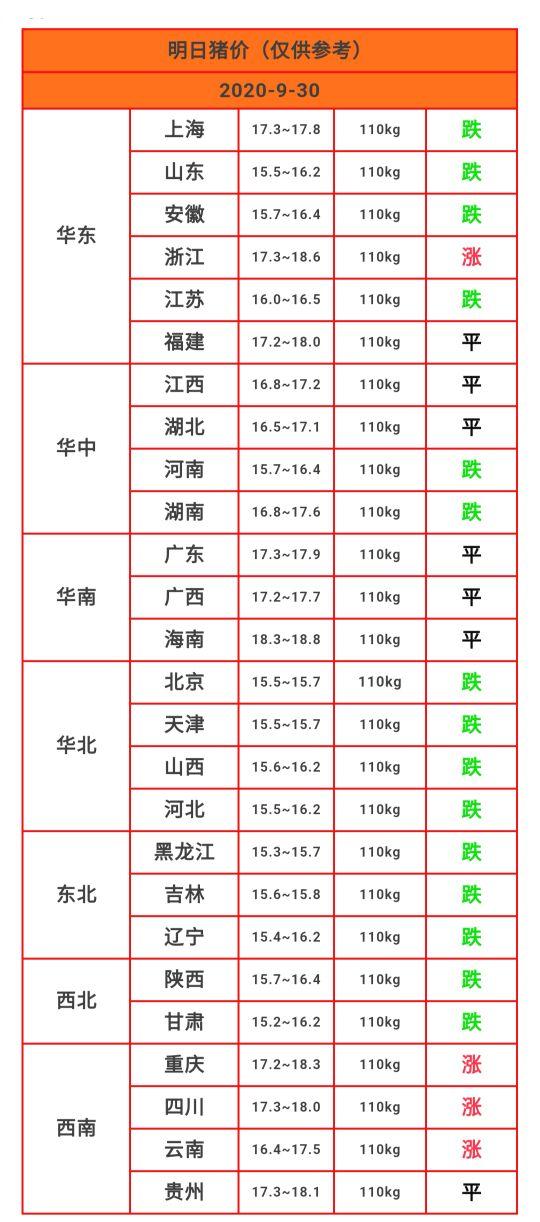
继续下跌!今日猪价生猪价格表最新 9月30日猪肉价格多少钱一斤
今天是九月的最后一天,生猪市场的收盘价不是很理想,明天的两节的到来还没有提振猪价,但是,十五个省市出现了大规模的下跌,尤其是在 东
-
西安发现北宋孟氏家族墓地 为重要宋代考古新发现
陕西省考古研究所17日透露,考古学家在西安市长安区郭杜街道杜回村南部挖掘出汉、唐、宋、金、明、清时期墓葬40余座。其中,北宋晚期的5座
-
今日海南疫情最新数据情况公布 海南新增4例境外输入病例
海南新增4例境外输入病例,均为巴拿马籍货船上中国籍船员。那么,对于海南此次的疫情,今天的你是否也在持续关注着呢?具体什么情况?下面跟小
-
文在寅被扔鞋让人大跌眼镜 文在寅是韩国罪人?
我们都知道韩国总统文在演是一位非常优秀的总统,但是近来文在寅被扔鞋让人大跌眼镜,到底是什么样原因竟然会让深受人爱戴的总统被丢鞋呢?
-
7月25日南京江宁区疫情实时数据公布:20日以来南京共报告本土确诊
刚刚通报!南京新增3处中风险地区,目前本土确诊共35例。那么,对于南京疫情的这个话题,今天的你是否也在关注着?具体什么情况?下面跟小编一